



Bleunomics is working on sophisticated computationally-derived drug discovery pipelines aimed to target the clinical level. We hope to work with potential partners for validating data and submitting FDA INDs or 501(K)s for new drugs, devices, tools and discoveries.
We utilize a variety of complex technologies for the clinical drug discovery process.
We design complex DNA computing and genotyping chipsets as well as storage methods.
We work extensively on data mining target results or advanced sequences.
Bleunomics utilizes advanced statistical and ranking approaches for its analysis.
We utilize computationally-derived techniques for complex immunotherapy by design.
We run a variety of simulations for the data validation and quality checks.
Next we target and simulate a variety of approaches for clinical delivery.
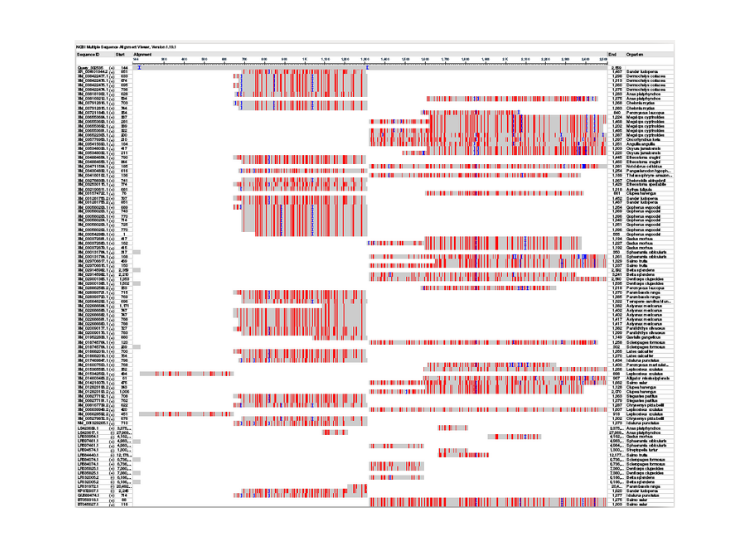
Currently, Bleunomics is targeting a variety of different genetic mutations and disorders. We have contributed to the Genbank sequence for BankIt2430198 Lepisosteus MW62911, as well as done independent sequences from other researchers' FASTA data including generating a VSF from the pre-existing AP014690.1 FASTA utilizing freebayes, vcfy and a distributed computing network. Bleunomics also done experimental protein synthesis, PCR priming, and reactionary simulations.
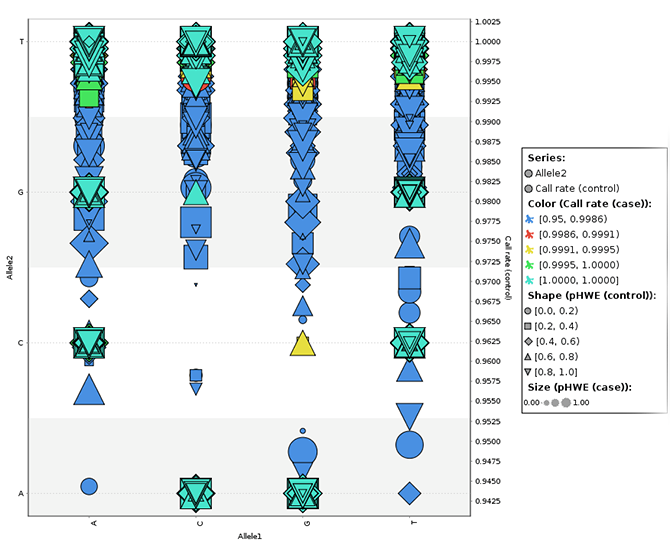
We utilize extensive data analysis and visualization techniques for genomic data. Along with our techniques, we integrate statistical methodologies in order to quickly see the data that is needed to be seen. Some of our approaches are novel and new.
Bleunomics is involved in a variety of scientific computing, genomic analysis, and data visualization projects.
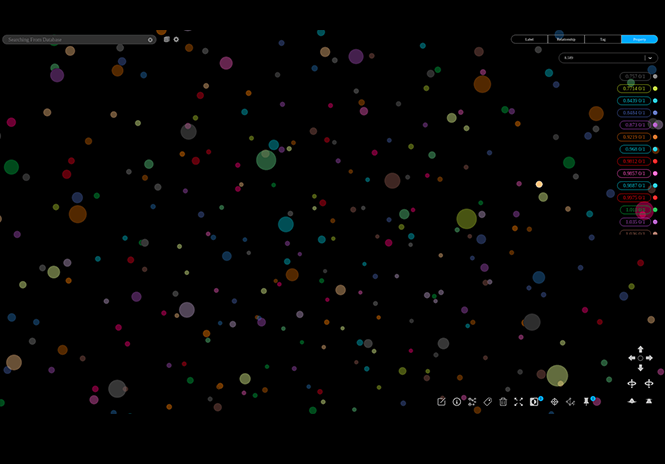
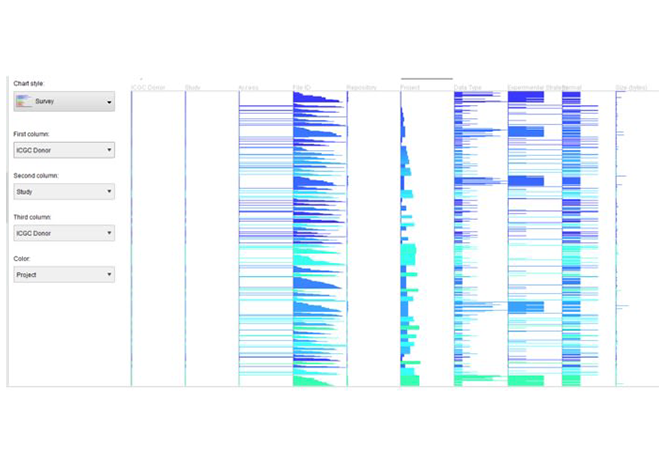
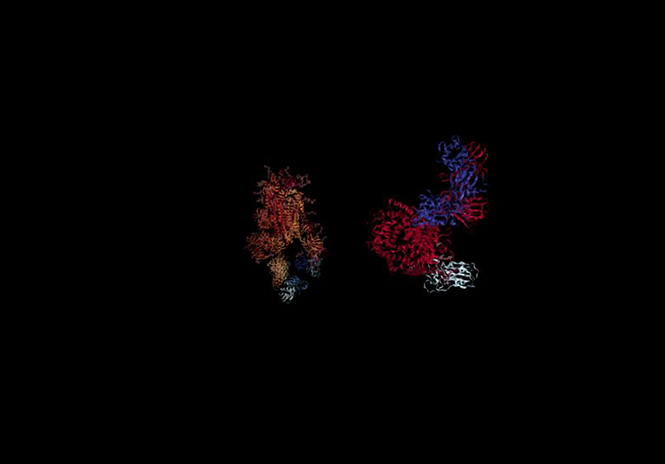
Bleunomics contributes to a large array of vastly efficient research areas.

Distributed computing and parallel processing are often used for offloading large amounts of data in instances such as BOINC. Projects, such as the Decentralized-Internet SDK also allow for people to build instances of cluster computing projects for the offloading of data or decentralized architecture.
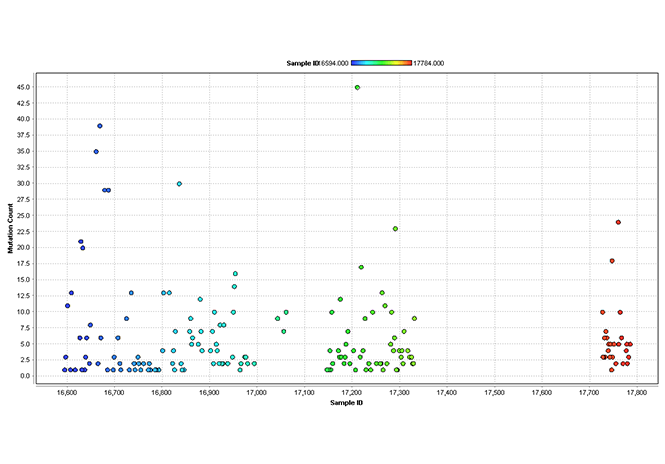
Utilizing RapidMiner, one can perform regressional analysis and indicative data visualization for cancer genomics case studies in open bio portals. The analysis of cancer on the cellular level utilizing hierarchical algorithms and a data mining program such as RapidMiner is critically helpful in providing researchers the information they need.

Conventional data visualization software have greatly improved the efficiency of the mining and visualization of biomedical data. However, when one applies a grid computing approach the efficiency and complexity of such visualization allows for a hypothetical increase in research opportunities.

The usage of Quantum Similarity through the equation Z={∀ θ∈ Z→∃ s∈ S∧∃ t∈ T: θ=(s, t)}, represents a way to analyze the way communication works in our DNA. Being able to create the object set reference for z being (s, t) in our DNA strands, we are able to set logical tags and representations of our DNA in a completely computational form.

Computationally artificially derived chemical synthesis and multistep preparation processes can have a variety of use-cases. The idea of utilizing advanced computational complexity, bleu-score computational ranking type systems, and isolating different variable data is integrated in the synthesis preparation processes. Some use-cases presented include: edible polymers and the field study of printable foods, synthetic carbon capturing polymers and biomasses, and CBD Isolate for phytocannabinoids.